Announcing Letta

We are thrilled to introduce Letta. Letta is building the memory management platform for the next generation of agentic systems. We are continuing the research done through the MemGPT project at UC Berkeley, as well as building a production-ready platform to make it easy for developers to create and launch stateful agents and LLM APIs.
Our vision
Today, memory for LLMs is often an afterthought. The primary way developers use LLMs is through stateless API calls, where the developer manages the state of their program, and the LLM API server runs a single pass of inference using the provided inputs. This model of programming with LLMs works for simple chat applications, where the only state the client needs to manage is a chat history. However, applications built on top of LLMs are becoming increasingly complex - LLMs are now being used not only to generate chat messages, but also call tools, connect to external data sources, communicate with other agents, and perform multi-step reasoning. In these settings, the stateless API model of LLM programming starts to fall apart - crucially, developers need better primitives for programming an LLM’s context window, or “memory”, based on the state of their AI program.
We believe innovations in the stateful layer above the base LLM are the new frontier in AI research. Since the release of GPT-4, we’ve seen much of the progress, both from LLM model providers and startups alike, come from using models more effectively, rather than through new model architectures or scaling parameters. OpenAI’s release of o1 (in absence of GPT-5) is an example of how the focus from the frontier foundation model companies is shifting away from scaling at training time to “scaling at inference time” - in other words, orchestrating the LLM inference to leverage techniques such as extended chain-of-thought, reflection, search, and self-editing memory to increase the reasoning capabilities of the base model.
Unfortunately, as the ambitions of closed AI model providers grows beyond their base models, so does the risk to developers using their APIs. Imagine a future where the most powerful model in the world is not only owned by a private corporation, but is also only usable via a closed API that prevents you from seeing any model outputs related to its reasoning steps. Your agent’s memories may be hidden too, and are trapped in a single provider, locking you into the initial model you built it with. This isn’t a fictional dystopia, it’s today’s reality.
At Letta, we’re building the open platform for developing stateful AI applications. Our mission is to innovate at the LLM orchestration layer, and to bring these innovations to developers in a transparent, controllable way, while also ensuring that developers can always swap model providers without losing data. A key principle of our platform is separation of data and compute for LLM applications by managing memories and state in a model agnostic manner. We’re betting on a future where the market for models is competitive (rather than a monopoly or duopoly), and applications that have the flexibility to move across model providers.
What’s next
We are currently developing an Agent Development Environment (ADE), based on the Development Portal that was part of the MemGPT project. The ADE is intended to make it easy to develop, debug, and deploy stateful agents in a single interface. The ADE can be connected to both your own deployed Letta service (via the OSS) or through our hosted service.
We are also beginning to pilot Letta Cloud, a hosted version of the Letta service that manages state and agent execution, and can be connected to external inference providers (e.g. OpenAI, Anthropic, vLLM, and more).
If you’re interested in seeing a demo of the ADE or getting early access to the Letta Cloud, you can also sign up for early access here.
Letta will continue to develop and maintain the MemGPT open source software (permissively licensed under Apache 2.0), though the package names will be shifted to Letta to make clear the distinction between MemGPT agents vs. the Letta agent framework (you can see more with our OSS announcement). At Letta, we are continuing the research done through the MemGPT project in advancing agent design and memory systems. We intend to continue to make our research open: we believe the next frontier for advancements in AI is memory management, and we believe that it is critical for agent memory and reasoning to be white box for AI developers to fully understand and control their applications.
Thank you!
We are incredibly grateful to the MemGPT community, the UC Berkeley research community, and the Letta team for getting us to this point. If you are interested in (or have feedback on) our products, please email us at [email protected] or sign up for early access.
If our vision excites you: we are building an incredible founding team of engineers and researchers in San Francisco, please apply to join us!
The name “Letta” stems from an approximation of the word “Letter”. LLMs are simply token in, token out - yet we can build incredibly complex, intelligent systems based on this simple abstraction. Letta is building the memory management platform for agentic development, all without hiding how these systems run on top of token (or “letter”) generation.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.



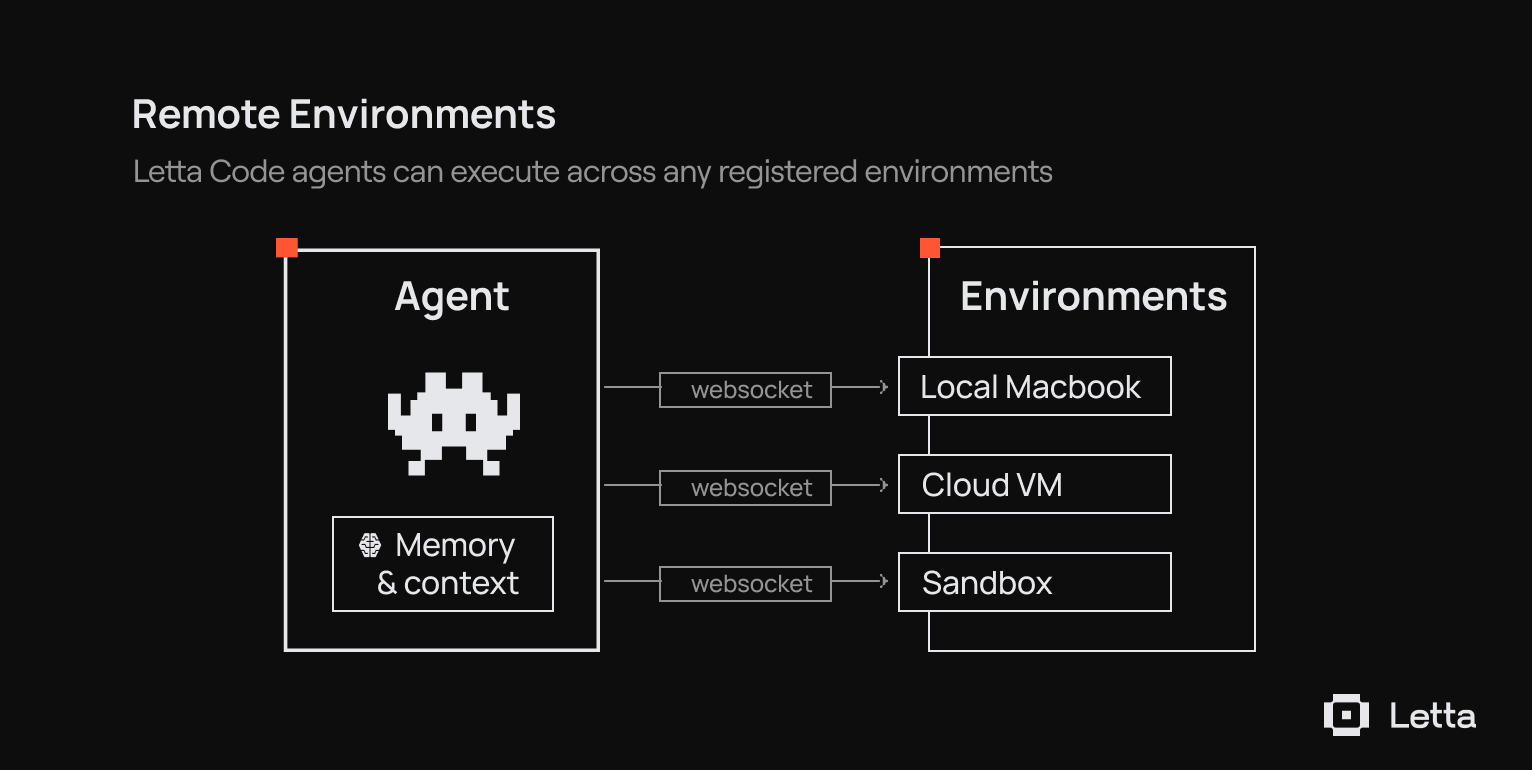
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.


.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

