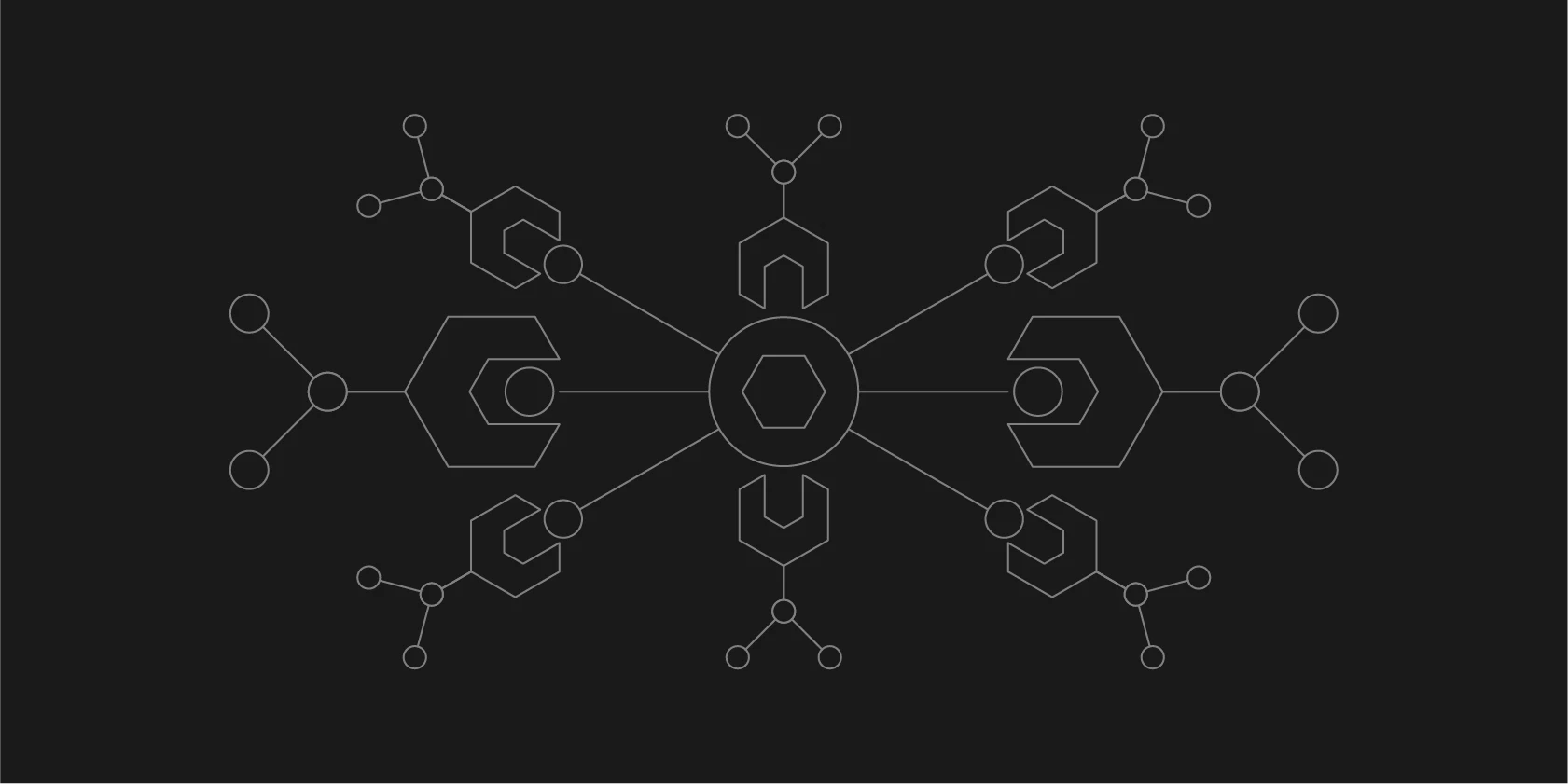
The AI agents stack

Understanding the AI agents landscape
Although we see a lot of agent stack and agent market maps, we tend to disagree with their categorizations, and find they rarely reflect what we observe actually being used by developers. The agent software ecosystem has developed significantly in the past few months with progress in memory, tool usage, secure execution, and deployment, so we decided it was time to share our own “agent stack” based on our own learnings from working on open source AI for over a year and AI research for 7+ years.

From LLMs to LLM agents
In 2022 and 2023 we saw the rise of LLM frameworks and SDKs such as LangChain (released in Oct 2022) and LlamaIndex (released in Nov 2022). Simultaneously we saw the establishment of several “standard” platforms for consuming LLMs via APIs as well as self-deploying LLM inference (vLLM and Ollama).
In 2024, we’ve seen a dramatic shift in interest towards AI “agents”, and more generally, compound systems. Despite having existed as a term in AI for decades (specifically reinforcement learning), “agents” has become a loosely defined term in the post-ChatGPT era, often referring to LLMs that are tasked with outputting actions (tool calls) and that run in an autonomous setting. The combination of tools use, autonomous execution, and memory required to go from LLM → agent has necessitated a new agents stack to develop.
What makes the agent stack unique?
Agents are a significantly harder engineering challenge compared to basic LLM chatbots because they require state management (retaining the message/event history, storing long-term memories, executing multiple LLM calls in an agentic loop) and tool execution (safely executing an action output by an LLM and returning the result).
As a result, the AI agents stack looks very different from the standard LLM stack. Let’s break down today’s AI agents stack, starting from the bottom at the model serving layer:
Model serving

At the core of AI agents is the LLM. To use the LLM, the model needs to be served via an inference engine, most often run behind a paid API service.
OpenAI and Anthropic lead among the closed API-based model inference providers with private frontier models. Together.AI, Fireworks, and Groq are popular options that serve open-weights models (e.g. Llama 3) behind paid APIs. Among the local model inference providers, we most commonly see vLLM leading the pack for production-grade GPU-based serving loads. SGLang is an up-and-coming project with a similar developer audience. Among hobbyists (”AI enthusiasts”), Ollama and LM Studio are two popular options for running models on your own own computer (eg M-series Apple Macbooks).
Storage

Storage is a fundamental building block for agents which are stateful - agents are defined by persisted state like their conversation history, memories, and external data sources they use for RAG. Vector databases like Chroma, Weaviate, Pinecone, Qdrant, and Milvus are popular for storing the “external memory” of agents, allowing agents to leverage data sources and conversational histories far too large to be placed into the context window. Postgres, a traditional DB that’s been around since the 80’s, also now supports vector search via the pgvector extension. Postgres-based companies like Neon (serverless Postgres) and Supabase also offer embedding-based search and storage for agents.
Tools & libraries

One of the primary differences between standard AI chatbots and AI agents is the ability of an agent to call “tools” (or “functions”). In most cases the mechanism for this action is the LLM generating structured output (e.g. a JSON object) that specifies a function to call and arguments to provide. A common point of confusion with agent tool execution is that the tool execution is not done by the LLM provider itself - the LLM only chooses what tool to call, and what arguments to provide. An agent service that supports arbitrary tools or arbitrary arguments into tools must use sandboxes (e.g. Modal, E2B) to ensure secure execution.
Agents all call tools via a JSON schema defined by OpenAI - this means that agents and tools can actually be compatible across different frameworks. Letta agents can call LangChain, CrewAI, and Composio tools, since they are all defined by the same schema. Because of this, there is a growing ecosystem of tool providers for common tools. Composio is a popular general-purpose library for tools that also manages authorization. Browserbase is an example of a specialized tool for web browsing, and Exa provides a specialized tool for searching the web. As more agents are built, we expect the tool ecosystem to grow and also provide existing new functionalities like authentication and access control for agents.
Agent frameworks

Agent frameworks orchestrate LLM calls and manage agent state. Different frameworks will have different designs for:
Management of agent’s state: Most frameworks have introduced some notion of “serialization” of state, that allows agents to be loaded back into the same script at a later time by saving the serialized state (e.g. JSON, bytes) to a file — this includes state like the conversation history, agent memories, and stage of execution. In Letta, where all state is backed by a database (e.g. a messages table, agent state table, memory block table) there is no notion of “serialization” since agent state is always persisted. This allows for easily querying agent state (for example, looking up past messages by date). How state is represented and managed determines both how the agents application will be able to scale with longer conversational histories or larger numbers of agents, as well as how flexibly state can be accessed or modified over time.
Structure of the agent’s context window: Each time the LLM is called, the framework will “compile” the agent’s state into the context window. Different frameworks will place data into the context window (e.g. the instructions, message buffer, etc.) in different ways, which can alter performance. We recommend choosing a framework that makes the context window transparent, since this ultimately is how you can control the behavior of your agents.
Cross-agent communication (i.e. multi-agent): Llama Index has agents communicate via message queues, while CrewAI and AutoGen have explicit abstractors for multi-agent. Letta and LangGraph both support agents directly calling each other, which allows for both centralized (via a supervisor agent) and distributed communication across agents. Most frameworks now support both multi-agent and single-agent, since a well-designed single-agent system should make cross-agent collaboration easily implementable.
Approaches to memory: A fundamental limit to LLMs is their limited context window, which necessitates techniques to manage memory over time. Memory management is built-in to some frameworks, while others expect developers to manage memory themselves. CrewAI and AutoGen rely solely on RAG-based memory, while phidata and Letta use additional techniques like self-editing memory (from MemGPT) and recursive summarization. Letta agents automatically come with a set of memory management tools that allow agents to search previous messages by text or data, write memories, and edit the agent’s own context window (you can read more here).
Support for open models: Model providers actually do a lot of behind-the-scenes tricks to get LLMs to generate text in the right format (e.g. for tool calling) — for example, re-sampling the LLM outputs when they don’t generate proper tool arguments, or adding hints into the prompt (e.g. “pretty please output JSON”). Supporting open models requires the framework to handle these challenges, so some limit support to major model providers.
When building agents today, the right choice of framework depends on your application, such as whether you are building a conversational agent or workflow, whether you want to run agents in a notebook or as a service, and your requirements for open weights model support.
We expect major differentiators to arise between frameworks in their deployment workflows, where design choices for state/memory management and tool execution become more significant.
Agent hosting and agent serving

Most agent frameworks today are designed for agents that don’t exist outside of the Python script or Jupyter notebook they were written in. We believe that the future of agents is to treat agents as a service that is deployed to on-prem or cloud infrastructure, accessible via REST APIs. In the same way that OpenAI’s ChatCompletion API became the industry standard for interacting with LLM services, we expect that there will eventually be a winner for the Agents API. But there isn’t one… yet.
Deploying agents as a service is much trickier than deploying LLMs as a service, due to the issues of state management and secure tool execution. Tools and their required dependencies and environment needs to be explicitly stored in a DB, since the environment to run them needs to be re-created by the service (which is not an issue when your tools and agents are running in the same script). Applications may need to run millions of agents, each accumulating growing conversational histories. When moving from prototyping to production, inevitably agent state must go through a data normalization process, and agent interactions must be defined by REST APIs. Today, this process is usually done by developers writing their own FastAPI and database code, but we expect that this functionality will become more embedded into frameworks as agents mature.
Conclusion
The agent stack is still extremely early, and we’re excited to see how the ecosystem expands and evolves over time. If you’re interested in hosting agents or building agents with memory, try out the Letta API and Letta Code.
Editors note: When making the AI agents stack diagram, we aimed to include companies and OSS that were representative of what software developers building a vertical agent application today (November 2024) would be most likely to use. Inevitably there are amazing companies and high-impact OSS projects that we missed - sorry if we missed you! If you’d like to be featured in a future stack diagram, please leave a comment on our LinkedIn post / Discord or shoot us an email.
Letta builds agents that learn. Agents with persistent memory, real computer access, and the infrastructure to improve from their own lived experience and work. Letta Code is the runtime that brings these together: git-backed memory, skills, subagents, and deployment that works across every model provider.

Traditional LLMs operate in a stateless paradigm—each interaction exists in isolation, with no knowledge carried forward from previous conversations. Agent memory solves this problem.

As AI agents become more sophisticated, understanding how to design and manage their context windows (via context engineering) has become crucial for developers.

Memory blocks offer an elegant abstraction for context window management. By structuring the context into discrete, functional units, we can give LLM agents more consistent, usable memory.

Although RAG provides a way to connect LLMs and agents to more data than what can fit into context, traditional RAG is insufficient for building agent memory.

Introducing “stateful agents”: AI systems that maintain persistent memory and actually learn during deployment, not just during training.




Today we’re launching the Letta Code app, a new way to interact with deeply personalized agents that learn over time and work locally on your machine.
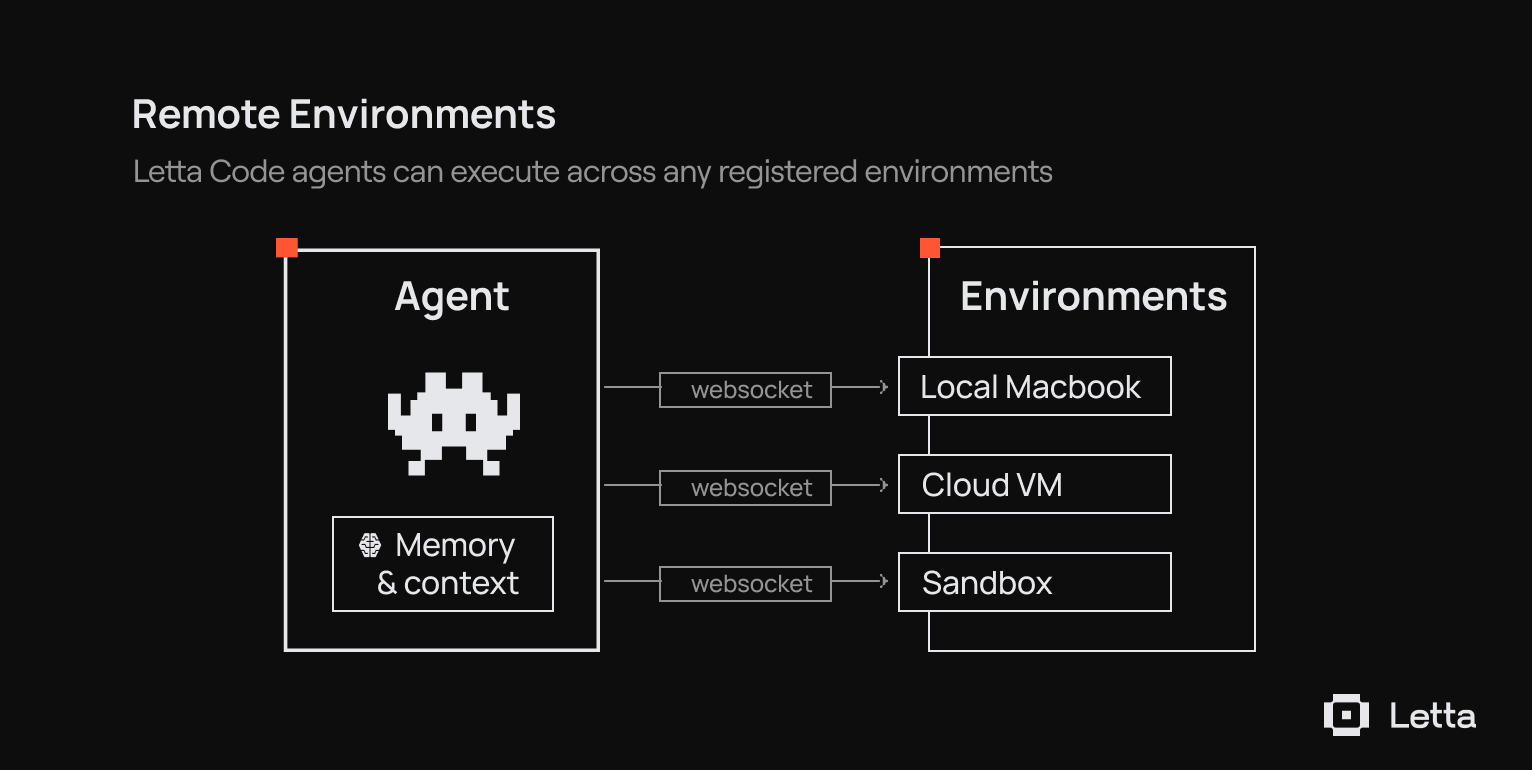
Using remote environments, you can message an agent working on your laptop from your phone.

The Conversations API allows you to build agents that can maintain shared memory across parallel experiences with users

Introducing Letta Code, a memory-first coding agent. Letta Code is the #1 model-agnostic open source agent on the leading AI coding benchmark Terminal-Bench.

The Letta API now supports programmatic tool calling for any LLM model, enabling agents to generate their own workflows.
Introducing Letta Evals: an open-source evaluation framework for systematically testing stateful agents.
Introducing Letta's new agent architecture, optimized for frontier reasoning models.
Letta agents can now take full advantage of Sonnet 4.5’s advanced memory tool capabilities to dynamically manage their own memory blocks.

Today we're announcing Letta Filesystem, which provides an interface for agents to organize and reference content from documents like PDFs, transcripts, documentation, and more.

We've releasing new client SDKs (support for TypeScript and Python) and upgraded developer documentation

Introducing Agent File (.af): An open file format for serializing stateful agents with persistent memory and behavior.

Introducing the Letta Agent Development Environment (ADE): Agents as Context + Tools

Letta v0.6.4 adds Python 3.13 support and an official TypeScript SDK.

Letta v0.5.2 adds tool rules, which allows you to constrain the behavior of your Letta agents similar to graphs.

Letta v0.5.1 adds support for auto-loading entire external tool libraries into your Letta server.



Today we are releasing the Context Constitution: a set of principles governing how AI agents manage context to learn from experience.
.png)
We're introducing Context Repositories, a rebuild of how memory works in Letta Code based on programmatic context management and git-based versioning.
At Letta, we believe that learning in token space is the key to building AI agents that truly improve over time. Our interest in this problem is driven by a simple observation: agents that can carry their memories across model generations will outlast any single foundation model.

Today we’re releasing Skill Learning, a way to dynamically learn skills through experience. With Skill Learning, agents can use their past experience to actually improve, rather than degrade, over time.

Today we're releasing Skill Use, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.

We are open-sourcing Context-Bench, which evaluates how well language models can chain file operations, trace entity relationships, and manage multi-step information retrieval in long-horizon tasks.

We're excited to announce Recovery-Bench, a benchmark and evaluation method for measuring how well agents can recover from errors and corrupted states.
Letta Filesystem scores 74.0% of the LoCoMo benchmark by simply storing conversational histories in a file, beating out specialized memory tool libraries.

We built the #1 open-source agent for terminal use, achieving 42.5% overall score on Terminal-Bench ranking 4th overall and 2nd among agents using Claude 4 Sonnet.

