


From test-time scaling to sleep-time scaling
Over the past year we’ve witnessed the rise of the “reasoning models”: models that "think" before they answer. Recent models such as OpenAI's o1, DeepSeek's R1, and Anthropic's Claude 3.7 don’t respond instantly, instead, they’ve been trained to output large reasoning traces before returning a final response. In certain application domains such as math and coding, allowing such a model to think for longer (anywhere from a few seconds to a few minutes) has been shown to significantly improve the “intelligence” of the model.
This approach, known as "test-time scaling", has proven incredibly effective at pushing the frontier of LLM-driven AI systems - the more we scale the reasoning at test-time, the better the results get. But what if we're only scratching the surface of what these systems could achieve? What if we've been severely underutilizing the potential of these powerful AI systems by only activating their reasoning capabilities when a user is actively waiting?
We believe there's a fundamental paradigm shift waiting to be unlocked: AI systems that don't just think reactively when prompted, but proactively deepen their understanding during what we call "sleep time" - the vast periods when they're not directly engaged with users.
This is the fundamental insight behind sleep-time compute, a new paradigm we're introducing in our latest research paper. Sleep-time compute represents an exciting new scaling direction for stateful AI systems: by activating deep thinking during their vast idle periods, we can expand what these systems understand and how they reason - pushing AI capabilities beyond what's possible when computation is confined only to active interactions.
Making machines think while they sleep
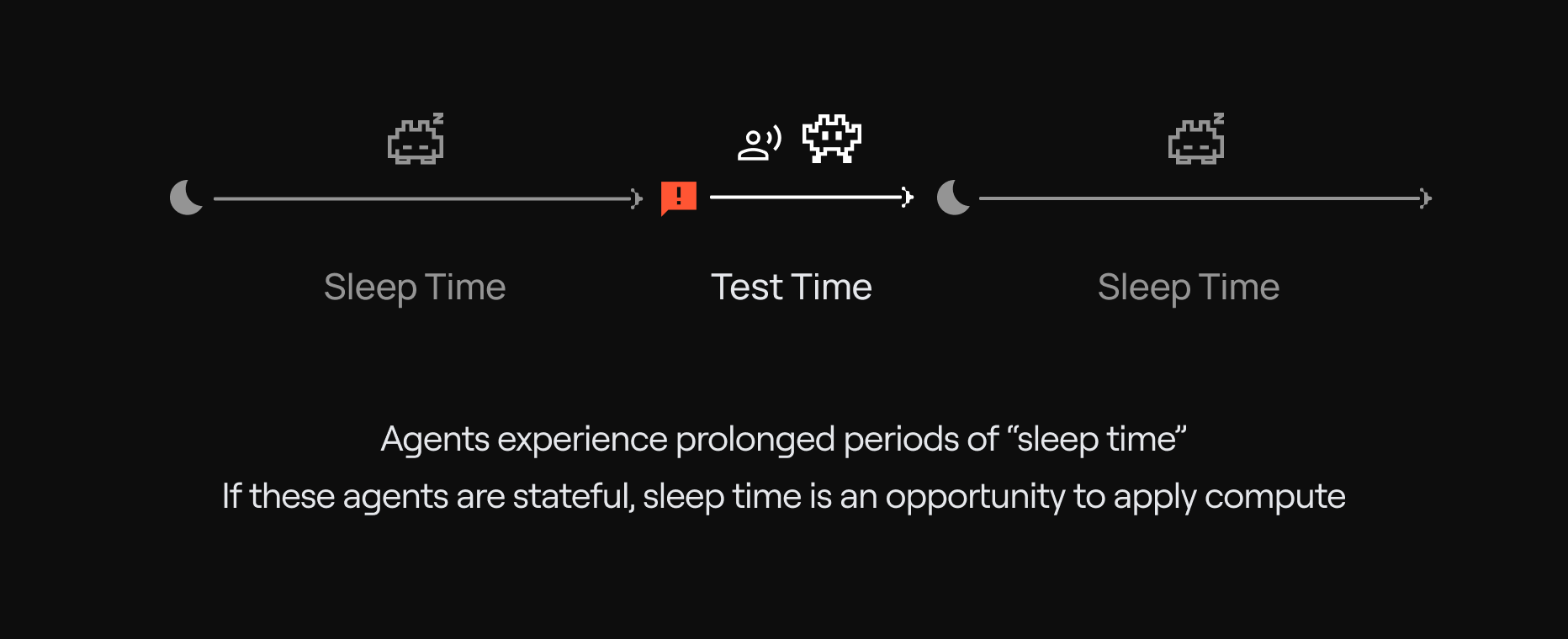
The key idea behind sleep-time compute is that our agents should be running even while they “sleep”, using their downtime to reorganize information and reason through the information they have available in advance. Many agents today exist in environments with persisted, re-used context: for example, a coding agent can study a codebase in advance of being asked to program in it, or a conversational agent can reflect on previous interaction from the user to consolidate information prior to interacting with the user again.
Reasoning during sleep time transforms “raw context” into “learned context”, which can then be used later during test time. Compared to agents which only have access to the raw context, agents that have the opportunity to compute a learned context don't need to perform as much additional reasoning later on, since they have already thought about the material in advance.
The crucial role of memory and state
Since the beginning of our work on MemGPT, our vision has been agents which are able to actually learn and evolve over time. Key to this is memory and state: despite their impressive capabilities, today's language models are fundamentally stateless, as they have no persistent memory of their experiences or learnings.
This limitation creates a critical bottleneck in how we can scale compute for AI systems. Traditional stateless models can only benefit from increased computation during active use (test time), because they reset between interactions. For stateless agents, any insights or connections made during downtime would simply vanish when the next interaction begins.
Sleep-time compute fundamentally requires stateful AI agents: systems that maintain memory (or context) over time. Persistent context forms the bridge that allows insights gained during sleep time to improve future capability.
Better cost and performance
Our research paper demonstrates that sleep-time compute creates a Pareto improvement in model performance. When tested on challenging math benchmarks like AIME and GSM, sleep-time agents are able to shift computational load from high-latency user interactions to periods when the system would otherwise sit idle, all without sacrificing performance quality. Additionally, we expect sleep-time compute to have significant impact beyond math and coding domains, benefiting conversational agents (through reflection on memories in the user's absence) and assistants (by enabling asynchronous ingestion of large data sources).
MemGPT 2.0: Sleep-time agents in Letta
We are releasing a new agent type in Letta, sleep-time enabled agents, which are based on the technique described in the sleep-time compute research paper.
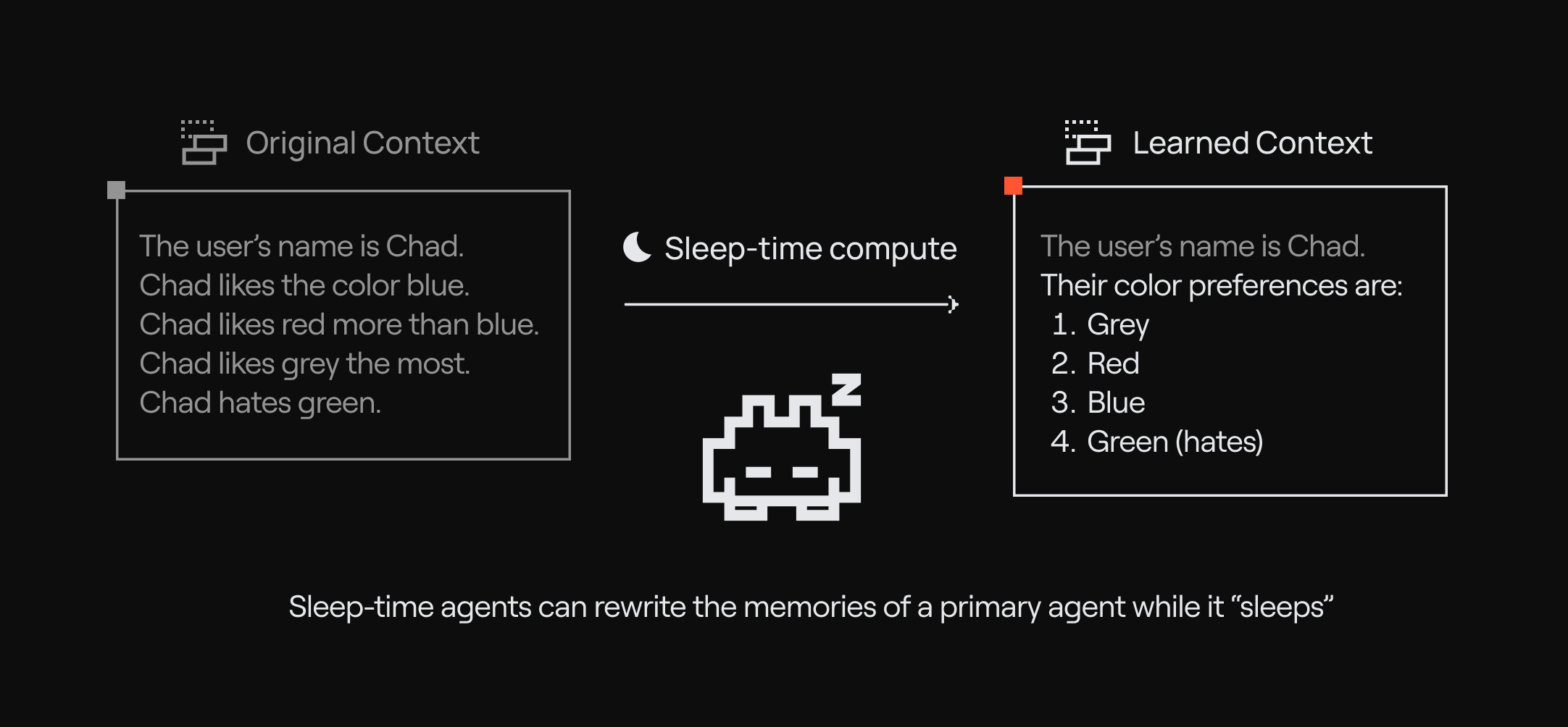
When you create agents with this type, Letta actually creates two agents under the hood: a primary agent and a sleep-time agent. The primary agent is similar to Letta agents today: it has the ability to send messages to the user, can call custom user tools, and can search its external memory (recall memory for conversation history, and archival memory for specifically saved memories). However the primary agent is not provided with tools to edit its core memory, which is the memory stored in-context composed of memory blocks. These tools are attached to the sleep-time agent, which has the ability to manage both the in-context memory of the primary agent as well as its own in-context memory.
This approach solves a number of problems with the original MemGPT agent design. In MemGPT, memory management, conversation, and other tasks are all bundled into a single agent, which means the agent may be slower (if it has to call memory operations during conversation) and potentially less reliable (since it calls both memory management tools and standard tools). Offloading memory to a sleep-time agent allows memory management to happen asynchronously. Memory formation in MemGPT is incremental, so memories may become messy and disorganized over time. Sleep-time agents on the other hand can continuously improve their learned context to generate clean, concise, and detailed memories.
Configuring sleep-time agents
Since Letta is model agnostic, the primary and sleeptime agents can be configured independently with different underlying models. We have found that it is useful to make the sleep-time agents stronger models since they are less latency constrained - for example, the conversational primary agent can use a fast model like gpt-4o-mini, while the sleep-time agent can use a larger and slower model like gpt-4.1 or Sonnet 3.7.
Sleeptime agents can also be configured to run at different frequencies. The higher the frequency setting, the more tokens your agent will use: but the more time the agent will have to revise its learned context.

Additionally, the sleep-time compute paradigm can be used to improve document analysis - you can upload a data source to your agent, and a sleep-time agent can parse it in the background, reading over the document and modifying the primary agent's memory to include all of the important findings. Importantly, the sleep-time agent modifies the memory in an “anytime” fashion - so the primary agent can read from this memory whenever, without having to wait for the sleep-time agent to finish its reasoning.
We anticipate that in the future, most agents in Letta will be sleep-time-enabled for better memory, personalization, and improved latency.
Conclusion
We've released our sleep-time agents as part of Letta 0.7.0. Try it yourself through through the Letta API and Letta Code.
We're excited to see how the community builds on these ideas to create AI systems that truly never stop learning.
Interested in working on research at Letta? Apply to join our team.