


As agents are deployed in the real world, it's impossible to endow them with everything they need to know ahead of time. Instead, agents must continually learn online, either by creating memories through experience, or by acquiring pre-made knowledge (or "skills") that extend their capabilities when needed. Skills enable agents to dynamically load specialized expertise, from statistical analysis methods to brand guidelines, without polluting their context with irrelevant information.
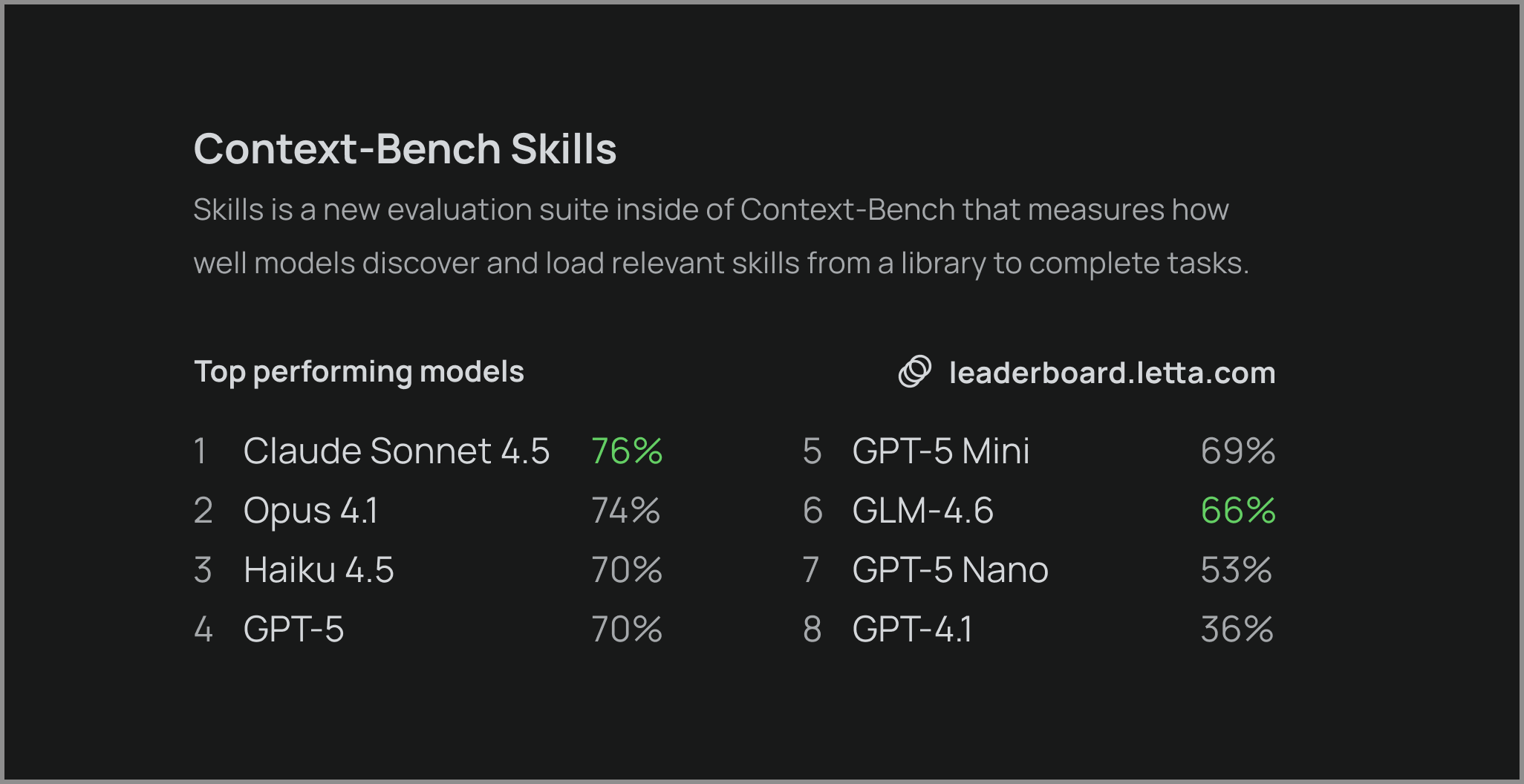
We recently released Context-Bench, which measures how well models can chain file operations and trace entity relationships to retrieve information. Today we're releasing Context-Bench Skills, a new evaluation suite inside of Context-Bench that measures how well models discover and load relevant skills from a library to complete tasks.
Our evaluation shows that many frontier models are quite capable at online skill acquisition with the right harness. As part of our evaluation, we've built skills into Letta Code, a model-agnostic harness that enables any LLM to use Anthropic's skill format. This means GPT-5, Gemini, and other models can now leverage the same skill library originally designed by Anthropic for Claude.
What are “Skills”? Enabling Agents to Acquire Context
Skills are mountable packages of specialized knowledge. Each skill is a directory containing a SKILL.md metadata file plus optional supplementary resources like datasets, scripts, and examples.
Importantly, an agent shouldn’t load every available skill at the start of a conversation - space in the context window is precious, so skills should only be mounted and unmounted when needed. An agent should know what skills are available, then only retrieve the ones relevant to the current task.
For example, an agent may have skills containing a corporate style guide that it can view when it becomes aware that it needs to write marketing content, or a skill with census data schemas that it loads only when analyzing demographic information.
Skills Are a Form of Context Mounting
Skills are an implementation of context mounting. Context mounting is Letta's term for managing specialized knowledge across the context hierarchy. Instead of loading everything upfront or searching through unstructured documents, agents follow the following process:
- Selection: Choose from available skills based on their metadata
- Mounting: Load the skill directory into the context window
- Execution: Apply the skill's knowledge to complete the task
- Unmounting: Free up context space when finished
Skills enable agents to have access to specialized expertise without overwhelming their context window. An agent might have dozens of skills available, but only consume tokens for the skills it actually mounts and uses.
Skill Structure
At their core, skills are just directories with files. Here's an example of a skill we created to help agents design effective Letta agents:

Agents using skills will always have access to the name (letta-agent-designer) as well as the description of what the skill does, and the agent can load the full contents of the skill file to fully understand how to design effective Letta agents only when it is working on a task related to designing a Letta agent.
But do skills actually work? The pattern is conceptually elegant, but has not yet been empirically measured. Anthropic released their skill library without accompanying evaluations about whether they improve agent performance. Do agents successfully identify when skills are relevant? Do they load the right skills at the right time? And crucially, does skill access improve task completion?
Adding Skills To Context-Bench
Today we’re releasing a new evaluation suite in Context-Bench, Context-Bench Skills, which measures the ability of an agent to utilize an available skills library to complete tasks. We use Anthropic’s open-source skills library (e.g. creating slack GIFs, algorithmic art, MCP servers) as a starting point to synthetically generate suitable tasks for each skill using a separate (LLM-based) task generator.
The key idea is that for a given task, there exists a relevant skill that will help the agent solve it - so if the agent is good at using skills, it will “acquire” the skill in order to complete the task. Specifically, given a randomly-selected skill at task generation time, the task generator:
- Loads the skill by reading its SKILL.MD and file structure for additional resources
- Generates a unique task that requires only the selected skill to complete adequately
- Creates rubrics to evaluate task completion and appropriate skill use
At test-time, we use a model-agnostic skills-compatible agent harness (Letta Code) to evaluate the agent’s ability to use skills to complete tasks. We evaluate agents in three settings:
- Baseline: The agent doesn’t have access to any skills.
- Skill Use: The agent provided the required skill metadata, but must still load relevant skill data (e.g. the skill body and files)
- Skills Selection & Use: The agent has access to all skills, so must both identify the required skill and use the skill
We evaluate the agent’s performance on each task by measuring task completion and skill use (via an LLM-as-a-judge rubric), and aggregate performance across all tasks. Agents that are good at using “skill acquisition” should be able to correctly identify the correct skill from the library and dynamically load it into their context to complete the task. Agents that are bad at skill use will either fail to load the skill, or load too many skills at once, polluting the context window with irrelevant information.
Results: How Useful Are Skills? Evaluating Claude’s Skill Library
Anthropic released their own library of skills without any quantitative evaluation showing they improve agent performance. Our results confirm that skills do work — for Claude models that are effective at skill use, providing the relevant skill improves task completion by an average of 14.1%.
We find that frontier models successfully use skills regardless of whether they were explicitly trained for it. Non-Anthropic models like GPT-5 and GLM-4.6 (open weights) achieve similar performance gains from skills, demonstrating that skill acquisition is a general capability rather than a Claude-specific feature.
The ability to select the correct skill from a library is harder than using a skill that's already been identified. Among the models that are good at using skills, performance drops by approximately 6.5% when the models need to find the right skill first compared to when the relevant skill is provided directly. This gap suggests room for improvement in how models discover and prioritize skills.

Skill Are a Model-Agnostic Primitive
Powerful models like GLM-4.6 (open weights) and GPT-5 (closed weights) effectively use and select skills without any special training, suggesting that general-purpose capabilities are sufficient for skill acquisition. However, weaker models like GPT-5 Mini and GPT-5 Nano show negligible improvements from skills. Even when provided with the skill metadata, these models fail to properly load and apply the skill content to complete tasks. This creates a clear capability threshold — models need sufficient reasoning ability before they can benefit from skills at all.
Skills Enable Continual Learning
Skills enable continual learning by decoupling knowledge creation from agent initialization. When one agent develops a solution or learns a new pattern, that knowledge can be packaged as a skill and made available to other agents. This creates a shared knowledge ecosystem where agents learn from collective experience rather than starting from scratch. Unlike fine-tuning or retraining, skills can be created, tested, and deployed immediately — agents acquire new capabilities in real-time as skills become available, and can “shed” skills when they no longer are needed for the task, freeing up space in their context window.
Letta Code: A Model-Agnostic Harness For Skills
Claude Code was the only agent harness that supported skills — until now. To evaluate skill use across different models, we built skill support into Letta Code, our CLI tool which allows interacting with stateful agents running on a remote Letta server directly in your terminal (currently available as an open source research preview).
The implementation leverages Letta's existing agentic context engineering architecture. We added a dedicated skills memory block that maintains metadata about available skills. Since Letta's memory blocks are always visible to the agent, it can discover and load skills dynamically during execution. The agent sees the list of available skills in its memory, decides which ones to load based on the task, and uses standard file operations to read the skill contents.
This means any model — GPT-5, Gemini, GLM-4.6 — can now use the same skill libraries originally built for Claude. The skills themselves are just directories with markdown files and resources, making them completely portable across agent frameworks.
What’s Next
Our evaluation demonstrates that skill acquisition works today: frontier models can successfully identify, load, and use skills to complete tasks they couldn't solve otherwise. With Letta Code providing model-agnostic skill support, any LLM can now leverage the growing library of skills being developed by the community. As agents are deployed for longer-horizon real-world tasks, their ability to acquire knowledge online will determine whether they can adapt to new domains without constant retraining.
To learn more, check out:
- The live-updated Context-Bench leaderboard: https://leaderboard.letta.com
- Letta Evals GitHub repo: https://docs.letta.com/evals
- Letta Platform: https://app.letta.com